
タイトルの通りですが、広報で使っている画像が
- 自社サイトのどこで使われているか(ページのURL)
をExcelで管理しようとなりました。
サイトを一つ一つ見て、どの画像を使っているかなんて記録するなんてめんどくさすぎるので、webスクレイピングで解決しようと思いました。
仕組みの概要ですが、以下の通りです。
- (事前準備)自社サイトで掲載している”画像の”名前(aaaa.png とかそういう感じ)
- (事前準備)その画像に誰が載っている
- 調べたいサイトの一番上流のページを指定(例えばhttps://webscraper.io/test-sites/e-commerce/allinone だったら、https://webscraper.io)
- そのページから辿る事が出来る、そのサイトの内部のページを全て検索し、シートのA列にある画像がページに含まれているか確認(https://webscraper.io 以外のサイトは見ない※Twitterとか)
- 含まれていたページのURLをC列に、”, “区切りで出力
この事前準備のところにある「誰が載っているか」の部分も、表記ゆれや入力の手間を考えて、VBAを使って名前を入力してもらおうと考えました。なので、本ページは以下の構成です。
- Excel VBAで「名前一覧」から複数選択できるユーザーフォームを作り
- PythonでWebスクレイピングを行い、結果を同じExcelに自動書き戻す
1. Excel VBAで「名前一覧」から複数選択できるユーザーフォームを作る
前提・準備
- Windows版Excel(マクロ有効ブック:
.xlsm) - リボンに「開発」タブが見えていること(なければファイル→オプション→リボンのユーザー設定で有効化)
- VBAエディタを開く(
Alt+F11)
フォルダ構成イメージ
InputBook.xlsm(マクロ有効ブック)- table シート:
テーブル名:T_name
※テーブル名の編集の仕方はこちらを参考にしてください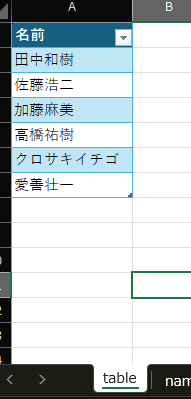
- scraping シート:B列でフォーム起動(テストで2つの画像をA列に入れてる)
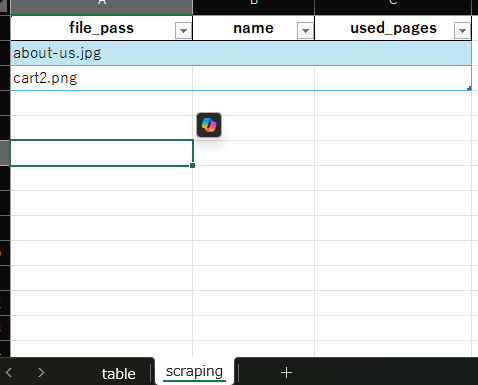
- table シート:
ステップ1:標準モジュールのModule1に「ShowNamePicker」を作成
まず、VBAエディタで挿入 → 標準モジュールを選び、Module1に以下を貼り付けます。
' Module1.bas
Option Explicit
' ダブルクリックされたセルをフォームに渡すグローバル変数
Public TargetCell As Range
' シートのBeforeDoubleClickイベントから呼び出すサブルーチン
Sub ShowNamePicker()
Dim uf As UserForm1
' フォームのインスタンスを作成
Set uf = New UserForm1
' 操作対象のセル(ActiveCell)をフォームに渡す
Set uf.TargetCell = ActiveCell
' フォームを表示(Initialize → Activate が自動実行)
uf.Show
End Subステップ2:UserForm1を作成し、コントロールを配置
- VBAエディタの挿入 → UserFormでフォームを追加
- プロパティウィンドウでフォーム名を
UserForm1に設定 - Toolboxから以下をドラッグ&ドロップし、プロパティを設定。(左下のところにプロパティを編集できるところがあります)
| コントロール | Name | Caption | 主な設定 |
|---|---|---|---|
| ListBox | lstNames | (空欄) | MultiSelect = fmMultiSelectMulti |
| Label | lblPreview | (空欄) | (そのまま) |
| CommandButton | btnOK | OK | (そのまま) |
| CommandButton | btnCancel | キャンセル | (そのまま) |
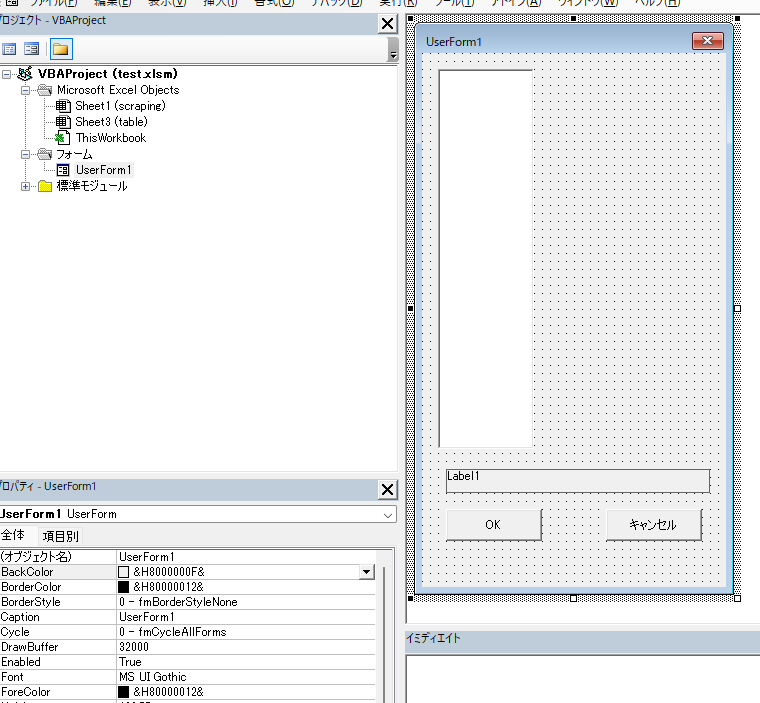
各ブロックのサイズは、見やすいように大きくしちゃいました
UserForm1 のコードを貼り付け
左メニューにあるUserForm1を右クリック→「コードの表示」をして、以下を丸ごと貼り付けてください。
' UserForm1
Option Explicit
' Module1 から渡された「編集対象セル」
Public TargetCell As Range
' 初回ロード:tableシートの T_name から名前を読み込む
Private Sub UserForm_Initialize()
Dim ws As Worksheet
Dim tbl As ListObject
Dim cel As Range
' 名前一覧を置いた「table」シートを指定
Set ws = ThisWorkbook.Worksheets("table")
Set tbl = ws.ListObjects("T_name")
' ListBox をクリアしてから項目を追加
Me.lstNames.Clear
For Each cel In tbl.DataBodyRange.Columns(1).Cells
Me.lstNames.AddItem cel.Value
Next cel
End Sub
' フォーム表示時:既存セル値をプレビュー&選択状態に反映
Private Sub UserForm_Activate()
Dim existing As String
Dim arr As Variant
Dim v As Variant
Dim i As Long
If Not TargetCell Is Nothing Then
existing = CStr(TargetCell.Value)
Me.lblPreview.Caption = existing
If existing <> "" Then
arr = Split(existing, ",")
For Each v In arr
v = Trim(v)
For i = 0 To Me.lstNames.ListCount - 1
If Me.lstNames.List(i) = v Then
Me.lstNames.Selected(i) = True
Exit For
End If
Next i
Next v
End If
End If
End Sub
' ListBoxが変わるたびプレビューを更新
Private Sub lstNames_Change()
Dim sel As String
Dim i As Long
sel = ""
For i = 0 To Me.lstNames.ListCount - 1
If Me.lstNames.Selected(i) Then
If sel = "" Then sel = Me.lstNames.List(i) _
Else sel = sel & ", " & Me.lstNames.List(i)
End If
Next i
Me.lblPreview.Caption = sel
End Sub
' OKボタン:プレビュー内容をセルに書き戻す
Private Sub btnOK_Click()
If Not TargetCell Is Nothing Then
TargetCell.Value = Me.lblPreview.Caption
End If
Unload Me
End Sub
' キャンセル:何もせず閉じる
Private Sub btnCancel_Click()
Unload Me
End Subステップ3:scrapingシートにダブルクリックイベントを設定
最後に、左メニューからscrapingシートをダブルクリックし、右のエディター上に下記を貼り付けます。

Option Explicit
Private Sub Worksheet_BeforeDoubleClick(ByVal Target As Range, Cancel As Boolean)
' B列(列番号2)限定、1セルだけを対象
If Target.Column = 2 And Target.Cells.Count = 1 Then
Cancel = True ' 通常編集をキャンセル
ShowNamePicker ' Module1 のフォーム表示サブルーチン呼び出し
End If
End Sub動作イメージ
- scrapingシートの任意のB列セルをダブルクリック
- UserForm1が開き、左側に
tableシートの名前一覧(T_name)が縦並びで表示 - 複数選択すると、下のプレビュー領域(lblPreview)に即時反映
- 「OK」を押すと、B列セルに「山本, 田中, 佐藤」のように入力
以上の設定で、ExcelのVBAに不慣れな方でもドラッグ&ドロップで簡単に
- 名前の表記ゆれを防ぎ
- セルへの直接入力の手間を減らし
- リアルタイムプレビューで入力ミスを防ぐ
――という便利なユーザーフォームを実現で来たと思っています!!
次から、画像がどこで使われているか検索するプログラムを書きます。
ステップ4:PythonでWebスクレイピング&Excel自動更新
続いて、Pythonを使ってWebサイトをクロールし、指定画像が使われているページURLをExcelに書き戻す方法をご紹介します。初心者向けに手順とコードを解説します。
前提
- Pythonがインストール済み(Windowsなら
python --versionで確認)
pythonインストール方法はこちら - Excelファイル(.xlsmでもOK)をスクリプトと同じフォルダに置く(上記のVBAを実装したなら.xlsmになっているはずです)
- 必要なライブラリはターミナルでインストール:
pip install requests beautifulsoup4 pandas openpyxl tqdm openpyxlスクリプトの動作イメージ
- Excelの
test.xlsmから画像パスリストを読み込む(名前は皆さんの好きに変えてね!) https://webscraper.io/以下をBFSクロール(←このリンクはご自身の調べたいところのTOPページを指定してください~)- 各ページのHTMLに画像パスが含まれていればURLを記録
- マクロ情報を保持したままExcelのC列に書き戻す
Pythonスクリプト全文
スクリプトを実行するときは、Excel閉じてください!
#!/usr/bin/env python3
# coding: utf-8
"""
Excel (.xlsm) の scraping シートから画像パスを読み込み、
指定サイトをクロールして「どのページで使われているか」を調べ、
C列に自動書き戻すスクリプト
"""
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from collections import deque
import pandas as pd
from tqdm import tqdm
from openpyxl import load_workbook
# ── 設定セクション ──
INPUT_PATH = r"C:\Users\xxxx\Documents\test.xlsm" # そのExcelの絶対パスを指定
SHEET_NAME = "scraping" # 読み書きするシート名
START_URL = "https://webscraper.io/" # 調べたいサイトのURL
# ドメイン&パスを分割して定数化
PARSED_URL = urlparse(START_URL)
BASE_DOMAIN = PARSED_URL.netloc # "webscraper.io"
PATH_PREFIX = PARSED_URL.path # "/test-sites"
def normalize(url):
"""相対URLを絶対URLに変換"""
return urljoin(START_URL, url)
def is_within_site(url: str) -> bool:
"""同一ドメインかつ /test-sites 以下かどうかを判定"""
p = urlparse(url)
return (p.netloc == BASE_DOMAIN) and p.path.startswith(PATH_PREFIX)
def crawl_all(start):
"""
BFSでサイト内をクロールし、
(ページURL, HTMLテキスト) のリストを返す
"""
visited = set([start])
queue = deque([start])
pages = []
while queue:
url = queue.popleft()
try:
r = requests.get(url, timeout=10)
r.raise_for_status()
html = r.text
except:
continue
pages.append((url, html))
soup = BeautifulSoup(html, "html.parser")
for a in soup.find_all("a", href=True):
full = normalize(a["href"])
if full not in visited and is_internal(full):
visited.add(full)
queue.append(full)
return pages
def main():
# 1) Excelをpandasで読み込み
df = pd.read_excel(INPUT_PATH, sheet_name=SHEET_NAME, engine="openpyxl")
image_list = df.iloc[:, 0].dropna().astype(str).tolist()
if not image_list:
print("A列に画像パスが見つかりません。")
return
# 2) サイトクロール
print("サイトクロール開始…")
pages = crawl_all(START_URL)
print(f"取得ページ数: {len(pages)}")
# 3) マッピング:画像ごとに使われるページURLを収集
mapping = {img: [] for img in image_list}
for url, html in tqdm(pages, desc="ページ調査"):
for img in image_list:
if img in html:
mapping[img].append(url)
# 4) C列用リストを生成
results = [", ".join(mapping.get(img, [])) for img in image_list]
# 5) openpyxlでマクロ保持しつつC列を上書き
wb = load_workbook(INPUT_PATH, keep_vba=True)
ws = wb[SHEET_NAME]
# ヘッダー(1行目)に「used_pages」を設定
ws.cell(row=1, column=3, value="used_pages")
# 2行目以降に結果を書き込む
for i, val in enumerate(results, start=2):
ws.cell(row=i, column=3, value=val)
wb.save(INPUT_PATH)
print("完了:Excelに書き戻しました。")
if __name__ == "__main__":
main()
(しつこいですが、Excelが閉じていないとエラーになります….)
結果は、C列に出力されます。
A2セルにある画像データを検索し、A.htmlとB.htmlとC.htmlの3つで使っていたと判定された場合、
C2セルに
A.html, B.html, C.html
という感じで、C2セル内に”, “区切りで出力されます。

使い方まとめ
- 上記Pythonコードを
scrape_and_write.pyとして保存 - 同じフォルダに
test.xlsmを配置 - ターミナルで
python scrape_and_write.pyを実行 - 終了後、
test.xlsmのscrapingシートのC列に自動で結果が入る
これで実現できること
- Excel上で名前を簡単に複数選択できるフォーム
- 指定Webサイトのどこに、探したい画像があるかを自動調査してExcelに出力
プログラミング初心者でも上記をコピペ&実行すれば動作します。ぜひお試しください!
このスクレイピングしたデータをもとに、管理簿や集計表などに加工しちゃってください!

コメント