
郵便物の中身をPDFにして、ファイル名をつけて、担当者へ連絡する
こんな雑務を毎日せっせとやってますがダルすぎるので、chatGPTに相談。
chatGPTが「出来るよ!!!」っていうから、言われたとおりにやってみる+ついでにpython勉強できるし一石二鳥感。
なんか色々指定してもらったけど、会社のPCのセキュリティとかで制限があるので、Bプランのこれを選択!今日やることはこちら
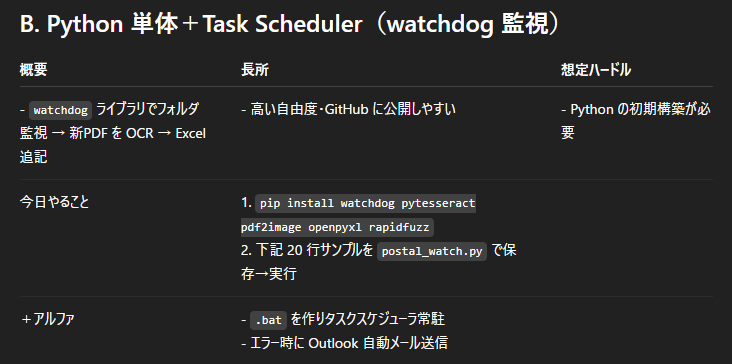
ぶっちゃけ何言っているかさっぱりだし、まずはpythonだとか色々とダウンロードしろってさ。
(めんd…)
このプログラムを組む前に、pythonだとかライブラリだとか色々とダウンロードさせられた。PowerShell(?)とか言うの触るの怖い….
ダウンロードしたもの一覧
Python 3.13 本体(Microsoft Store 版)
Python ライブラリ
- watchdog
- pytesseract
- pdf2image
- rapidfuzz
- openpyxl
- pandas
Tesseract-OCR 5.4.0(UB-Mannheim build, winget)←これのダウンロードめっちゃ苦労した
日本語学習データ jpn.traineddata(tessdata GitHub から Invoke-WebRequest で取得)
ダウンロードできました!と教官(chatgpt)に伝えたところ
まず書くのは “環境チェック用の超ミニスクリプト” だそうです。
# test_env.py ← 適当なフォルダに新規作成して保存
import pytesseract, pdf2image, rapidfuzz, pandas
from pathlib import Path
# --- ① Tesseract のバージョンと使用可能言語を表示 ---
print("Tesseract version :", pytesseract.get_tesseract_version())
print("Available langs :", pytesseract.get_languages(config=''))
# --- ② 部署マスターを読み込んで先頭5件だけ表示 ---
MASTER = Path("master_departments.txt")
if MASTER.exists():
with MASTER.open(encoding="utf-8") as f:
depts = [l.strip() for l in f if l.strip()]
print("部署マスター(先頭5件):", depts[:5])
else:
print("⚠ master_departments.txt が見つかりません")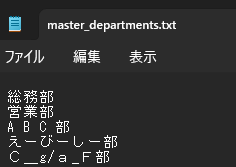
#結果
部署マスター(先頭5件): ['総務部', '営業部', 'A B C 部', 'えーびーしー部', 'С_g/a_F部']良い感じ!次だ!!
ステップ 2|PDF 1 枚で OCR が本当に読めるか を試す
0 │ 前提チェック
項目 確認コマンド OK なら Poppler が入っている pdftoppm -hヘルプが出る 日本語 OCR が通る tesseract --list-langs→jpnあり次へ進む
またPowerShellか…はいはい、やりますよ…
PDFに文字が埋め込まれていたらそのテキストを出力
もし文字が埋め込まれていなければ画像から検出
from pdfminer.high_level import extract_text
from pdf2image import convert_from_path
import pytesseract
PDF = r"C:\scan\test.pdf"
text = extract_text(PDF)
if not text.strip(): # テキスト層が空 → OCR
image = convert_from_path(PDF, dpi=300)[0]
text = pytesseract.image_to_string(image, lang="jpn")
print(text[:200])結果(200文字まで)
ご あ い さ つ(cid:0)
高齢化の進展に伴い、がん、心臓病、脳卒中などの生活
習慣病が増え、その結果、痴呆や寝たきりになる方が増えてい
ます。 子どもから高齢者まで、府民一人ひとりがいきいきと暮ら
せる社会をつくる上で健康は何よりも重要です。(cid:0)
京都府では、本年スタートした 2010 年に向けた京都府づくり
の基本方針となる「新京都府総合計画」において、「生涯になんか、(cid:0)って何やねんって感じだし、改行とかもすごい気になるけど、とりあえず出来た(?)って事で。

次のステップで、PDFに書いてある部署がどこなのかを判定するためスコア計算ライブラリを使うとのこと。
PDFから抽出した文字の一覧から、txtにある部署名の一覧(もしくは指定した部署だけ)とを比較して、比較したスコアが高かったらそれに応じて動くプログラムを書く事になったんだけど、ふと
「なんかライブラリ使いまくってるけど、アップデートとか技術が新しくなったらどーするんだろこれ」
と不安に思ったのでchatgptに聞いたら
「Python やライブラリが変わったら壊れそう…」— その不安を無くす 7 つの鉄板ルール
# 何をする? どうやる? もらえる安心感 1 プロジェクトごとに仮想環境を切る bash<br>python -m venv .venv # or conda create -n postal-ai<br>.venv\\Scripts\\activate # ← 以後このシェルだけで作業OS 全体を汚さず、ライブラリ衝突ゼロ 2 バージョンをピン留め requirements.txtにpdfminer.six==20221105のように “==” 固定
→bash pip install -r requirements.txt“昨日まで動いたのに今日は動かない” を根本から防ぐ 3 pip-tools で “凍結” bash<br>pip install pip-tools<br>pip-compile # → requirements.txt を完全固定化依存の孫・ひ孫バージョンまで記録 4 自動テスト 1 本だけ書く 例: tests/test_ocr.pypython<br>def test_jpn():<br> assert 'jpn' in pytesseract.get_languages(config='')<br>Python を 3.13→3.14 に上げても pytest一発で異常を即検知5 Docker 化で“環境丸ごと凍結” Dockerfile \nFROM python:3.11-slim\nCOPY requirements.txt .\nRUN pip install -r requirements.txt\nCOPY . /app\nCMD [\"python\",\"postal_watch.py\"]\nPC を替えても docker runだけで同じバージョンが再現6 月イチで dependabot / pip-review bash pip-review --interactive
or GitHub の Dependabot PR を眺めてマージ「更新が来たがテストが通るなら採用」——壊れる前に把握 7 コードを“設定と処理”に分離 config.yamlにwatch_dir: C:\\scan\nthreshold: 80
→ Python 側はyaml.safe_loadで読むだけルールが変わっても Python を触らず 設定ファイルを書き替えるだけ
と回答。無知な僕が悪かったけど、もうパソコンにゴリゴリ環境作っちゃったじゃん!!!
先に言ってよ~(´;ω;`)
この他にも「あれできる?これできる?」って聞いたところ、PDFの座標を指定できるっぽいので
「ちょうど真ん中あたりにうちの担当者の名前あるかもだから、その辺だけ注意深く見て、担当者っぽいとこ見つけたらその人にメール送っといて」
みたいなことができるんじゃないかと空想してます。
僕がやったことはライブラリ入れてポンッ、だけの単純作業だけど、pythonの凄さを思い知らされた1日だったぜ…
仮想環境を作るのが割と一般的?らしいので、docker なるもので環境を明日作ろうと思う。
githubにも登録しなきゃだしね。

コメント